robots.txt
What Is a Robots.txt File?
A robots.txt file tells search engine crawlers (such as Googlebot) not to crawl a page of a website. It's basically a text file that gives instructions to Google.

source: keyCDN
For a more "technical" definition, here's how Wikipedia defines it.
The robots exclusion standard, also known as the robots exclusion protocol or simply robots.txt, is a standard used by websites to communicate with web crawlers and other web robots. The standard specifies how to inform the web robot about which areas of the website should not be processed or scanned.
NOTE: All major search engines (Google, Bing, Yahoo) accept robots.txt requests.
What Are Robots In SEO?
Robots is another name for search engine crawlers. They can also be referred to as spiders or bots.
These "robots" crawl websites, indexing information they uncover.
In the robots.txt file, robots are known as "user-agents."
There is no universal user-agent name — each search engine has its own name for its robots. Google's is called Googlebot. You would have to put the unique robots name into your robots.txt file.
You can however use an asterisk (*) to target all search engine robots. More on this later…
You can use the robots.txt website database to find the names of each search engines robots.
Robots = search engine crawlers (Googlebot for example)
Robots.txt = a text file with instructions for robots
Anatomy of a Robots.txt File
The robots.txt file starts with a basic format.
User-agent: X Disallow: Y
User-agent: identifies what search engine crawler the instructions are for.
Disallow: These are instructions for what page/area of a website the user-agent should ignore (not crawl.)
Let's try an example.
User-agent: Googlebot Disallow: /wp-admin/
This robots.txt file is telling Google's crawler to not crawl the /wp-admin/ path of the website.
There are some other important rules to know.
User-agent: *
Using an asterisk (*) will target ALL search engine crawlers.
Disallow: /
Using only a slash (/) will block ALL of your website.
You can see a full breakdown of all the different rules with Google's Useful robots.txt rules."

We should cover specific aspects of robots.txt more extensively.
User-agent
Each of the major search engines have unique user-agent name for their search crawlers. These include:
- Googlebot (Google)
- BingBot (Bing)
- Slurp (Yahoo)
Multiple user-agents can exist in a robots.txt file — it looks like this.
User-agent: Googlebot Disallow: /images
User-agent: BingBot Disallow: /junk
All the instructions (disallow, allow, crawl-delay) between the first user-agent and the second one, are for the first one. In the example above, Googlebot would be instructed to "disallow" /images. BingBot would crawl /images, but not /junk.
Remember: using the asterisk (*) makes the robots.txt directives applicable to ALL search engine crawlers.
Disallow
The disallow directive tells search engine robots not to crawl specific regions of your website. These can be specific files, pages or general sub-directories.
You have to specify a "path" for the disallow directive to take effect. Here's an example doing so.
User-agent: * Disallow: /images
The path in the example above is /images — this tells specified user-agents to not crawl this area of the website.
If you do not specify a path, nothing will be disallowed.
Remember: Using the slash (/) will block the entire website.
Allow
The allow directive does the opposite of the disallow directive. It exists because there are instances where you'd want to disallow a section of your website, but "allow" an individual element. You might want to block all images, except one.
Here's an example.
User-agent: * Disallow: /images Allow: /images/image01.jpg
The example above has told all search engines to not crawl all your images, except image01.jpg.
If you do not specify a path for the allow directive, nothing will happen, it will be ignored.
Sitemap
Robots.txt files can also gives directions to the XML sitemap of a website.
FYI: An XML sitemap is file that lists all the URLs of your website. It makes crawling of your website easier for search engines.
Here's an example of how sitemaps are used in a robots.txt file.
User-agent: * Disallow: /images Sitemap: https://www.devinschumacher.com/sitemap1.xml
This would lead all crawlers to your XML sitemap. Make sure that enter a full URL, like in the example above.
The sitemap directive is supported by all 3 of the big search engines: Google, Yahoo and Bing.
NOTE: You can use more than one XML sitemap in your robots.txt file.
Here's how it would look.
User-agent: * Allow: /images Sitemap: https://www.devinschumacher.com/sitemap1.xml Sitemap: https://www.devinschumacher.com/sitemap2.xml
This robots.txt file would instruct all search engine crawlers directions to both sitemaps.
Crawl-delay
The crawl-delay directive — technically an "unofficial" directive" is used to stop servers being overloaded. Sometimes search engine crawlers can overwhelm your host server with too many requests.
The crawl-delay directive gives your website's server some breathing room. It's not a permanent fix — the real problem is your server — this directive is a short-term solution.
Here's an example of how it's used.
User-agent: * Disallow: /images Crawl-delay: 10
This robots.txt file targets all search crawlers, blocking your /images path, with a crawl-delay value of 10.
The crawl-delay directive has a value usually somewhere between 0-30. These are seconds, as in how many seconds of delay.
Make sure that the crawl-delay directives comes after the disallow/allow directive/s.
IMPORTANT: The crawl-delay directive is not official, it is only acknowledge by some search engines.
Google does not support it — instead they have their own crawl delay settings, accessible through Google Search Console.
Bing and Yahoo do support it, but have their own unique instructions.
Comments
You can add comments to your robots.txt file by using a dash (#) before some text. These comments have absolutely no bearing on what is communicated to what specified user-agents. They are simply there for humans.
Here is an example.
#This robots.txt file is blocking all images User-agent: * Disallow: /images
You can also do it another way.
User-agent: * #This robots.txt file is blocking all images Disallow: /images
Formatting
How you format your robots.txt file is extremely important. If you don't format correctly, you might not communicate to search engines correctly. Hell, you might not even communicate at all.
You need to make sure that every directive (disallow, allow, sitemap, crawl-delay) has its own line. Here are some examples.
AVOID writing your robots.txt file like this. ✘**
User-agent: * Disallow: /images Allow: /Images/Image01.jpg
This will confuse the hell out of robots crawling your website.
INSTEAD write it like this. ✔**
User-agent: * Disallow: /Images Allow: /Images/image01.jpg
How To Create a Robots.txt File
Open up Windows notepad and enter your preferred user-agent/s and directive/s.

Save the file — give it "Robots.txt" filename.

Where to Put a Robots.txt File
A robots.txt file is placed at the root of your website — the top-level directory. This can be done through cPanel.

The URL will come out looking like this: https://www.example.com/robot.txt
Make sure the filename is robots.txt and remember that the URL for the file is case-sensitive.
It's really important that you get the URL right — search engines ONLY look for that URL.
For example, if your URL was https://www.example.com/images/robot.txt it wouldn't be found.
Why You Should Use Robots.txt
Ideally you should always use a robots.txt file. The instructions it gives search engines makes crawling that much easier (which will mean better SERP ranking.)
However, I'll give you some specific reasons why you'd use a robots.txt file.
Blocking Pages With Sensitive Information
There are certain pages on your website that you DON'T want search engines to crawl — pages with sensitive information.
Common examples might include:
- Admin/dashboard pages (/wp-admin/)
- E-commerce shopping cart pages (/cart/)
- Script pages (/script/)
- Common gateway interface pages/folder (/cgi-bin/)
- Forum community member private pages
Make sure you use the disallow directive on any pages with potentially sensitive information.
Maximizing Crawl Budget
Using a robots.txt file can help optimize your crawl budget.
Crawl budget is an SEO term for the amount of resources search engines use when crawling your website.
You see, there are millions of websites out there that need to be crawled. Google (and other search engines) only have so many resources. They must choose what pages are important and which aren't.
A robots.txt file can make sure your important pages get crawled, by giving directives to ignore the irrelevant ones.
Avoiding Duplicate Content
A robots.txt file with the right directives, can instruct search engine crawlers to ignore pages with duplicate content.
Common types of duplicate content page include:
- Printer version of a page
- E-commerce product descriptions
- Syndicated content across multiple domains
- E-commerce category pages
Blocking these pages from search engines will keep your website clean from any potential SEO penalties.
Best Practice
- How to create + where to place
- Each directive must have its own line
- One robots.txt file per subdomain
- Know the rules for different search engines
- Avoid the byte order mark
- Don't use the noindex directive
- Test your robots.txt file with Google Search Console
How to create + where to place
We covered this earlier, but I'll do so once more quickly.
- Open Windows notepad and enter in your user-agent/s and directive/s
- Save the text file as "robots.txt"
- Access your website's cPanel and create a new file named "robots.txt" at the root of your website
- Add the robots.txt text file to the new file named robots.txt
NOTE: Make sure the file you create at the root of your website comes out with the right URL.
Right URL = example.com/robots.txt
Wrong URL = example.com/images/robots.txt
Each directive must have its own line
I covered this earlier in the formatting section but we'll go over it again.
Each directive in your robots.txt file MUST be on its own line.
Here's an example of how you should write out a robots.txt file. ✔**
User-agent: * Disallow: /images Allow: /images/image01.jpg
Conversely, here's how you shouldn't do it. ✘
User-agent: * Disallow: /images Allow: /images/image01.jpg
One robots.txt file per subdomain
If you have multiple subdomains, you will need a robots.txt file for each one.
For example, https://devinschumacher.com would have a robots.txt file URL of https://devinschumacher.com/robots.txt.
https://devinschumacher.com would have a different one — https://devinschumacher.com/robots.txt.
This applies for all different variations of your website, ccTLDs included.
Know the rules for different search engines
Every search engine has their own rules regarding robots.txt files — you need to know at least the main ones.
For instance: did you know that Google and Bing give priority to the directive that is the longest?
Here are some examples to help you understand.
User-agent: * Disallow: /about/ Allow: /about/company/
Explanation: All search engines — except Google and Bing — are blocked from crawling /about/. The same is true for /about/company/ — only Google and Bing can crawl it.
See that? Because the allow directive is longer and more specific, Google and Bing prioritize it. It takes precedence over the disallow directive, despite below it chronologically. Google and Bing are allowed to crawl /about/ because it comes 2nd to them.
Here's another example.
User-agent: * Allow: /about/team/ Disallow: /about/
Explanation: No search engines, including Google and Bing, can crawl /about/. Everyone can crawl /about/team/.
Because the allow directive is both first in chronology and length, it is prioritized by all search engines. This includes Google and Bing. Because the disallow directive comes both second in chronology and length, all can crawl.
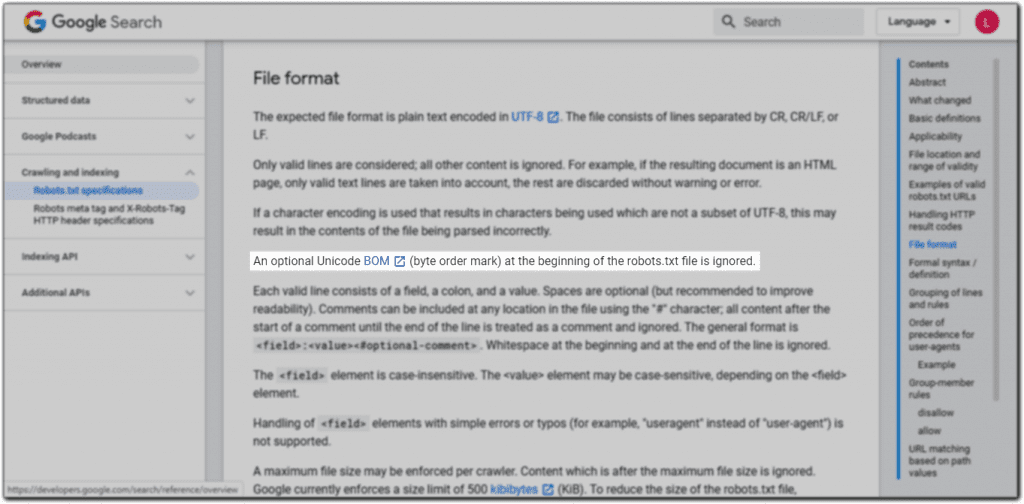
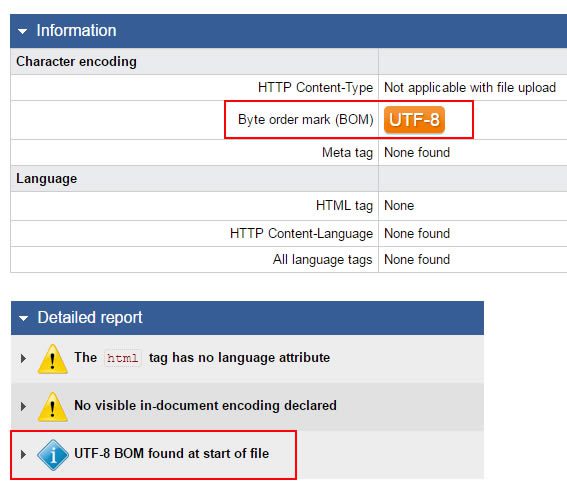
Avoid the byte order mark (UTF-8 BOM)
The byte order mark (UTF-8 BOM) is a unicode character that indicates the byte order of a file. It is entirely invisible to humans and literally serves no SEO function.
Because it has no bearing on SEO, it's not surprising Google straight-out ignores it.

If Google ignores it, then why should you even do anything about it?
Because not every search engine is like Google, and it (UTF-8 BOM) has shown to cause problems.
Sometimes, the byte order mark will "choke" the user-agent, causing it to error. When the user-agent stuffs up, everything else does too.
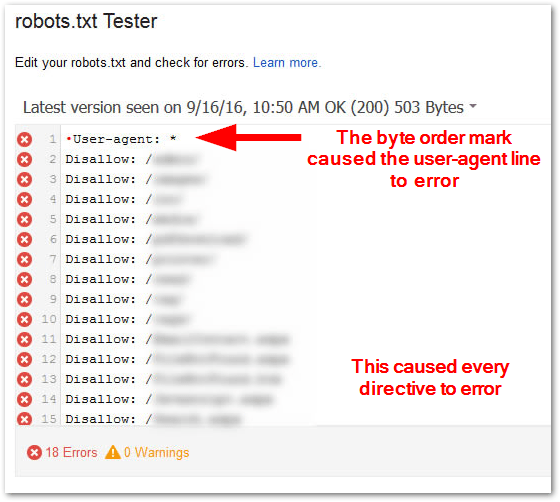
If you have Notepad++ (it's free) you can select to "Encode in UTF-8 without BOM."
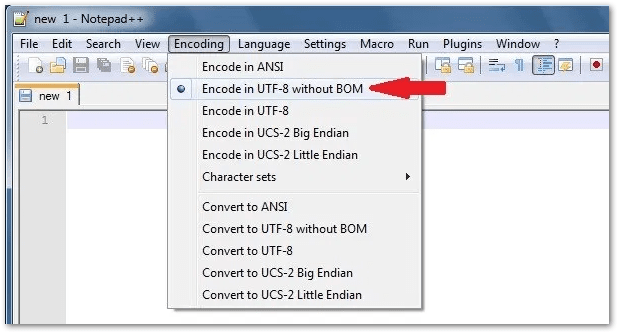
Textpad (another similar program) has a box you can "un-tick."

If you have a robots.txt that you're not sure has UTF-8 BOM, use W3C Internalization Checker to find out.
It will give you an answer.
Don't use the noindex directive
Did you know there is a "noindex" for the robots.txt file? It's technically unofficial, but it exists.
Google begrudgingly supported it for a long time, even when they said not to use it. But as of September of 2019 they officially stopped supporting it.
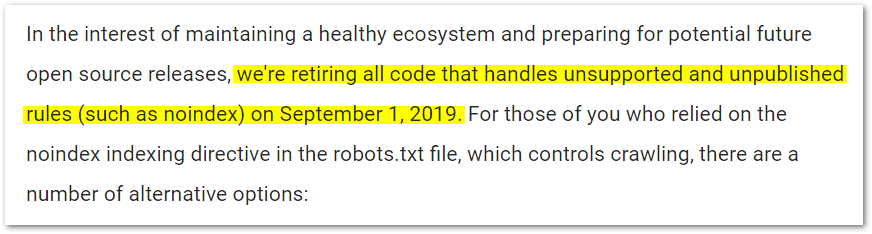
We're retiring all code that handles unsupported and unpublished rules (such as noindex) on September 1, 2019.
Bing is the same — apparently they never supported noindex, according to Frédéric Dubut (Bing Senior Program Manager Lead)
https://x.com/CoperniX/status/1146085846845554688?ref_src="twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E1146085846845554688&ref_url=https%3A%2F%2Fwww.contentkingapp.com%2Facademy%2Frobotstxt%2F"
Leave noindex for meta tags.
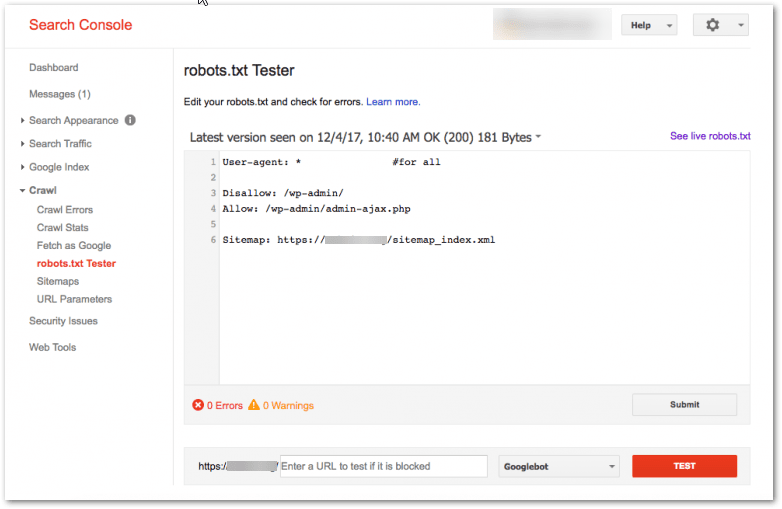
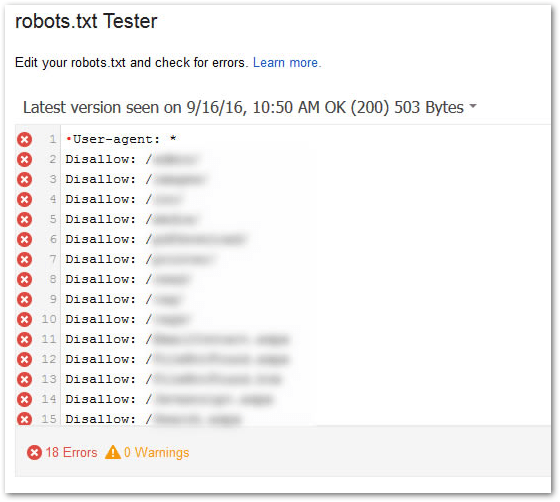
Test your robots.txt file with Google Search Console
One of the most important things you can do is test your robots.txt file. You can do this with Google Search Console.
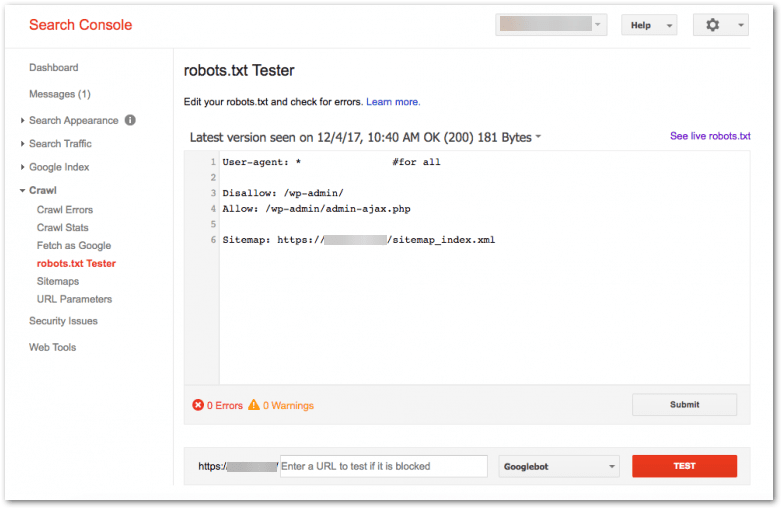
If your robots.txt has errors, it will let you know.
Final Thoughts
In this post we covered everything you need to know about the robots.txt file.
The robots.txt file is how you communicate with search engines, instructing their crawlers with directives. Knowing how the file works, how to write them and how to optimize them is crucial for SEO.