duplicate content
What Is Duplicate Content?
Duplicate content is when two pieces of content are exactly the same, or similar. This can be content on the same website, or two separate websites.

For good measure, here's Google's definition of "duplicate content."
Duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar.
Obviously instances of duplicate content will involve stealing from others, but lots of the time it happens in "non-sinister" contexts.
Here are some good examples.
- Printer-only version of a webpage (also known as printer-friendly)
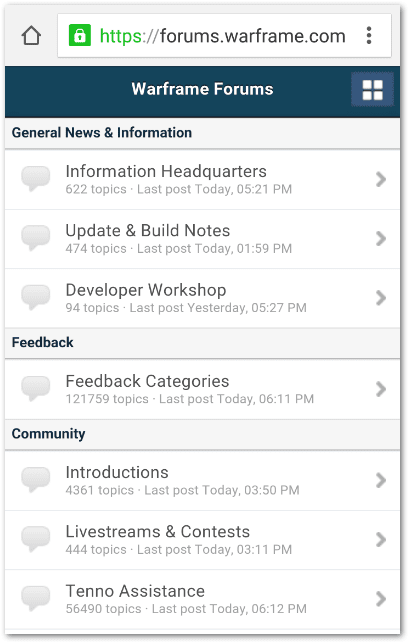
- Discussion forums with a mobile optimized version
- Commercial items with various different URL links (social, affiliate, etc)

How Does Duplicate Content Affect SEO?
Google does not want to index content that is not original — they want original, unique and informative content.
This is what Google (and other search engines) wants appearing on SERPs, not cut and paste content-spun dupes.
They even state this in their duplicate content guidelines."

A copied webpage is not a page with "distinct information."
Further down they emphasize the potential negative SEO consequences of duplicate content.

As a result, the ranking of the site may suffer, or the site might be removed entirely from the Google index, in which case it will no longer appear in search results.
Duplicate content can drop you in the search rankings, or get you de-indexed all together.
This is why it's important regarding SEO, and why we need to address it.
Best Practice
- Check Out What Pages Of Your Website Are Indexed
- Search The Internet For Duplicate Content Of Yours
- Check Your Website For Proper Redirection
- Use The Canonical Tag (When It Makes Sense)
- Use The 301 Redirect
- Utilize A Top-Level Domain For Country-Specific Content
- Use The Noindex Tag On Category And Tag Pages (WordPress)
Check Out What Pages Of Your Website Are Indexed
You need to find out what pages of your website are being indexed. This is the first step you should take.
It’s always good practice to check what pages of your website are showing up on Google.
You can check for indexed pages through Google Search Console.

The easiest way however, is to check through Google search.
To do this, search for “site:yourwebsite.com”
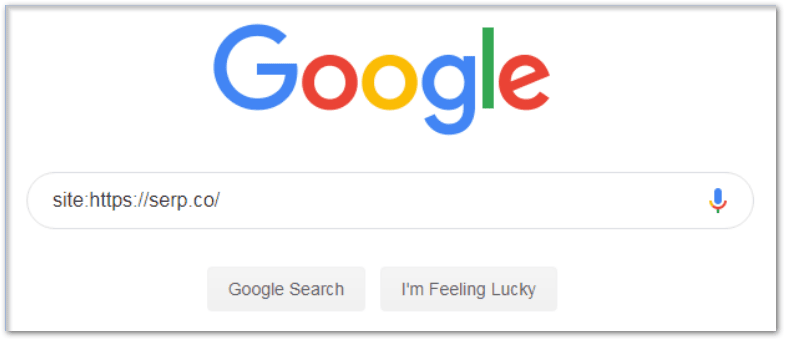
It should come up with all your ranking, indexed pages.
Check the number of results against the number of pages you have.
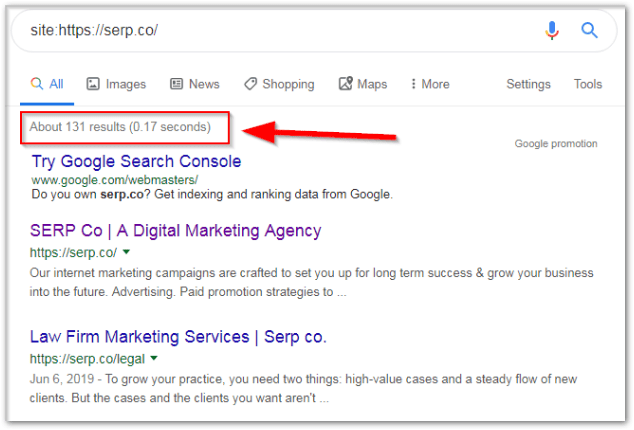
You should be able to find any "domestic" instances of duplicate content.
Alternatively you can use a tool specifically designed to find internal duplicate content — such as Siteliner.

It will give you an overview of your website, with a duplicate content analysis.
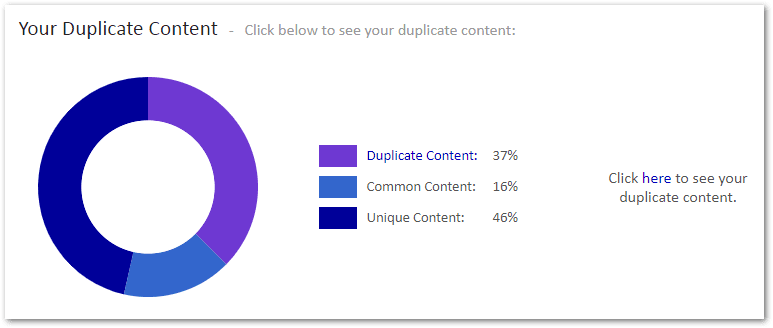
There is a premium version, but you should be covered with the free version.
Takeaway: Use Google Search Console, "site:yourwebsite.com" or Siteliner to find out what pages your website are being indexed.
Search The Internet For Duplicate Content Of Yours
You've done an internal duplicate content check, now it's time for an external one.
People will often rip-off your content and post it as their own. Unfortunately sometimes search engines give the original the boot as opposed to the copy/duplicate.
So let's track down these fakes — we'll do it with the help of Copyscape.

Copyscape is a plagiarism tool that can help you find out who's stealing your content.
Simply type your website address into the Copyscape search bar and 10 pages copying your content will appear.
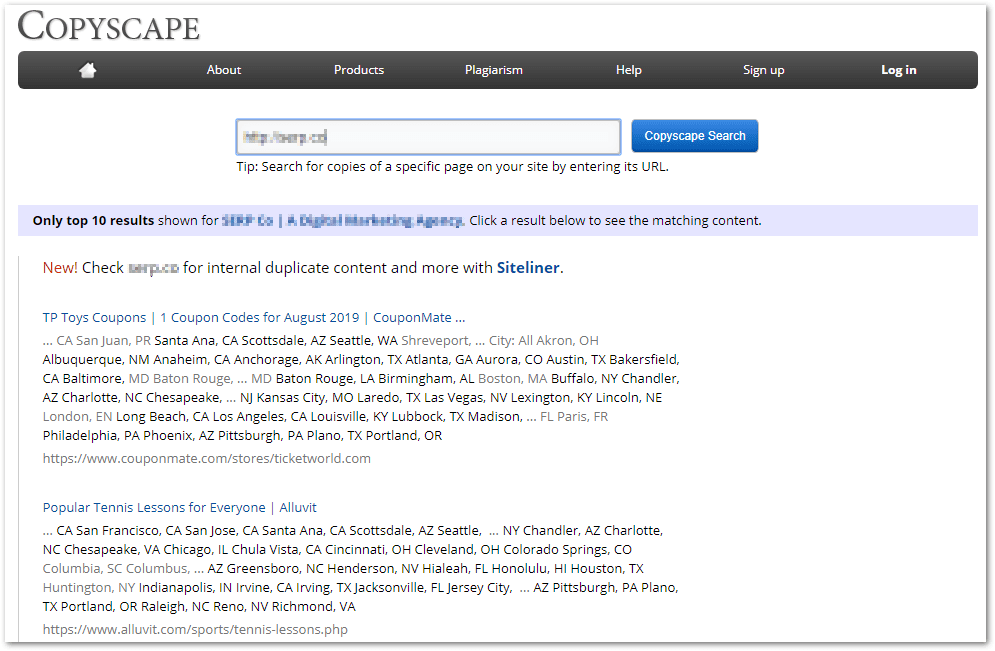
You can click on each result, and it will show the exact words copied (highlighted in pink) and a percentage.

Anything less than 40% is really nothing to worry about.
Takeaway: Use Copyscape to find people copying your content.
Check Your Website For Proper Redirection
People are often surprised to find out that they have multiple versions of the same website.
When you have multiple versions of your website, search engines — like Google — will treat it as a duplicate content situation.
It is rare, but it does happen.
There are 2 common scenarios where this might happen.
- Switching from HTTP to HTTPS.
- WWW site separate from non-WWW (www.google.com vs google.com)
You must make sure whatever variations of your site exist, go to the same one.
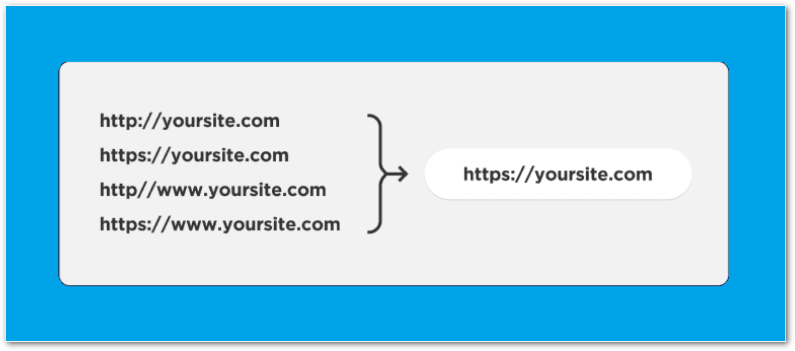
In the past you could address this issue with Google Search Console, but this no longer true.
On June 18 of 2019 Google removed the "preferred domain" setting.
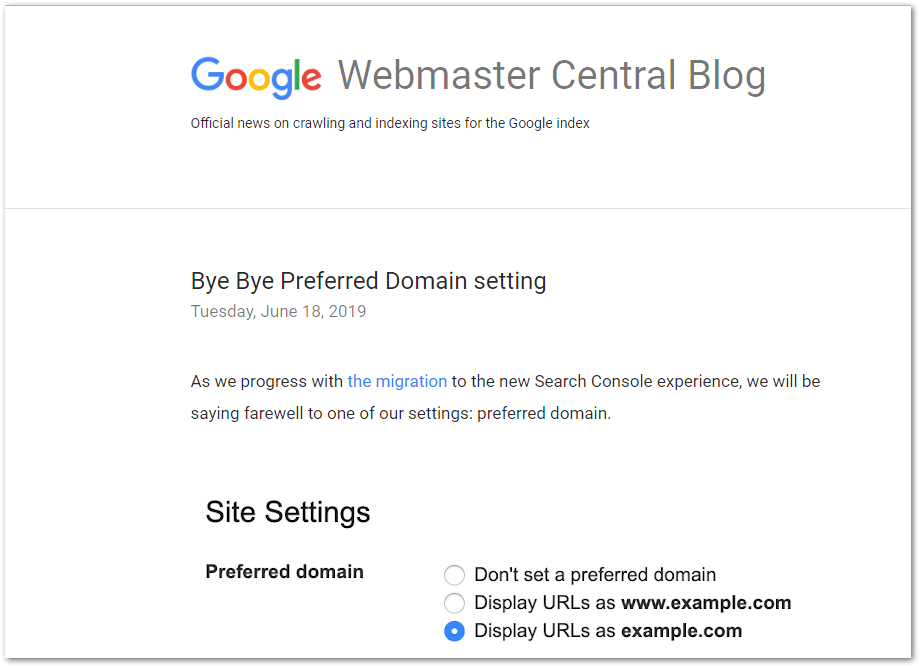
As an alternative, they outlined 4 strategies you could use.

- The canonical tag (HTML pages)
- The canonical tag (HTTP header)
- Sitemap
- 301 redirect attribute
The canonical tag and 301 redirect attribute will be covered later on in this post.
Takeaway: Redirect all versions of your website (http/https/www) to a single one.
Use The Canonical Tag (When It Makes Sense)
The canonical tag (rel="canonical)" is a HTML element that lets Google know what page is the original.

It basically says "this is the original piece of content, not the other ones."
When you communicate this to Google you are telling them to crawl, index and rank this webpage/content. You are telling Google to ignore the others.
This is one of the easiest and most effective ways to address duplicate content.
There are 2 ways you can use the canonical tag.
- Added to the HTML source code
- Added to the HTTP header
Adding it to the HTTP header is a little more technical — I'll just cover the HTML.
You can manually insert the tag straight into the HTML.
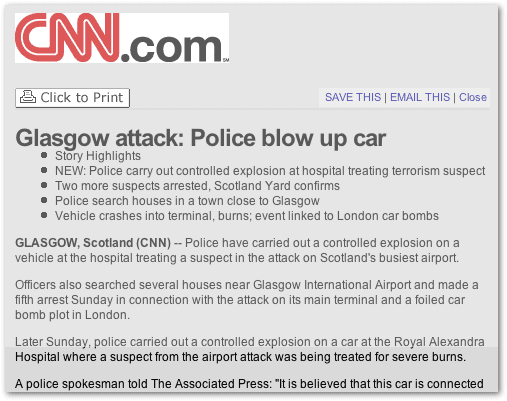
Here is an example from CNN.
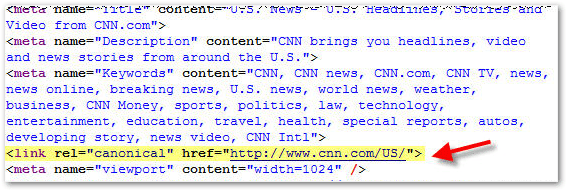
<link rel="canonical" href="insert link" />
Simply copy the example and plug in the desired link.
An easier way however, is to just do it with a CMS platform plugin.
WordPress SEO Plugin Yoast has a canonical tag form for pages/posts.
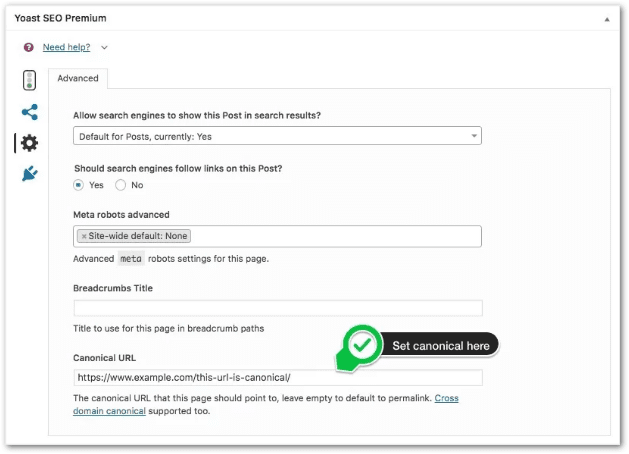
Takeaway: Use the canonical tag (rel="canonical)" to tell search engines a page is original.
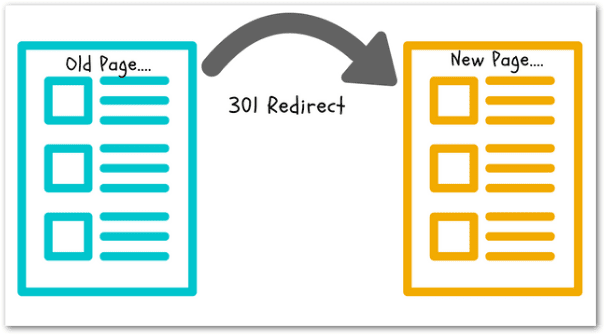
Use The 301 Redirect
A 301 redirect is a HTML code that permanently changes the direction of a link.
This is for both users and search engines.

Using a 301 redirect will transfer the "link juice" (link equity) to the new link.
It says to search engines "hey, everything you've crawled, indexed and ranked about this page? Please send it to this other page."
A 301 redirect is used when you want to update an existing page by creating a new page. It combines the two pages in a SEO sense.
The new page will be given all the SEO value from the old one, thanks to the 301 redirect.
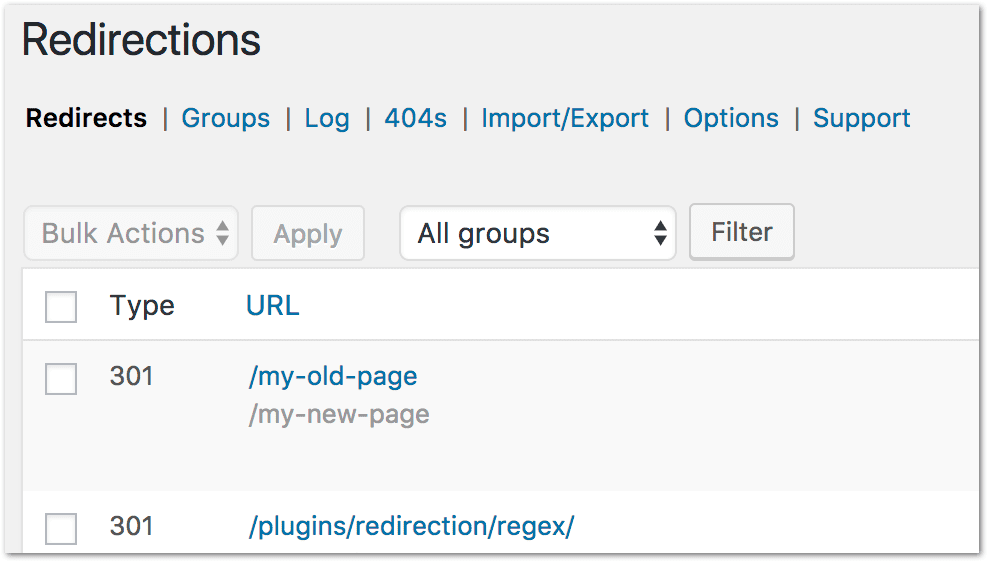
To use a 301 redirect you need to access your website's htaccess file — this can get technical.
Once again, the simpler option is to use a CMS plugin.
WordPress has plenty to choose from.
Takeaway: Use the 301 Redirect to re-route users and search engines to a new updated page.
Utilize A Top-Level Domain For Country-Specific Content
A top-level domain is the end part of a website address (domain) — the ".com" section.

There are 2 types of top-level domains.
- Generic top-level domains (gTLD)
- Country-code top-level domains (ccTLD)
Generic top-level domains are more common/universal, such as com, org and net.
Country-code top-level domains vary depending on the specific region.
For instance, South Africa uses za.

Australia uses au.

It's important that if you have duplicate content for different countries and languages, you might be penalized.
This is where the right ccTLD comes in handy.
A ccTLD helps to communicate to Google that you have multiple versions of your website and content for a reason.
Google even recommends it in their duplicate content guide."

To help us serve the most appropriate version of a document, use top-level domains whenever possible to handle country-specific content. We're more likely to know that
http://www.example.decontains Germany-focused content, for instance, thanhttp://www.example.com/deorhttp://de.example.com.
A ccTLD is only appropriate if your website operates in multiple countries.
There are also some downsides to using a ccTLD.
They can be quite expensive to maintain.
Each separate ccTLD website needs to build up its own domain authority — this can take time.
If ccTLDs are not a good choice for your needs, subdomains and subdirectories are your next best bet.
Takeaway: Use a country-code top-level domain to combat regional duplicate content issues.
Use The Noindex Tag On Category And Tag Pages (WordPress)
If you're using WordPress, you'll notice category and tag pages are automatically created.
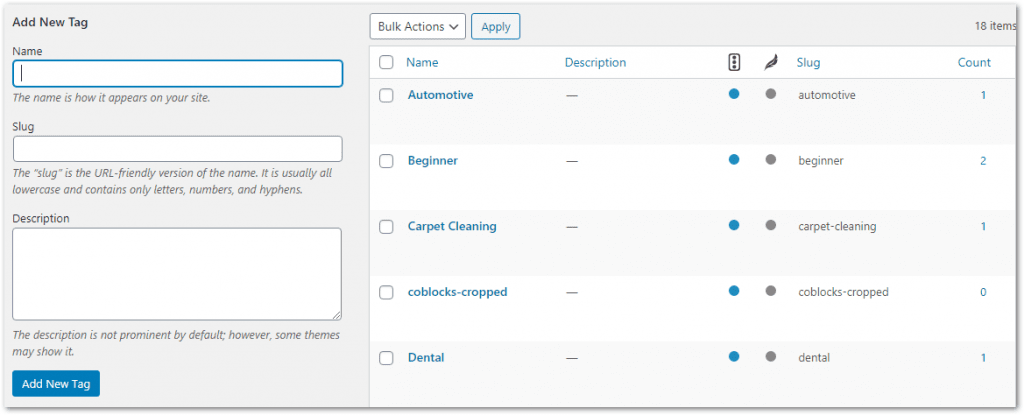
Category and tag pages are used to help website visitors and search engines navigate your content.
The problem with these pages is that they often cause duplicate content issues.
To combat this, you'll want to hit these pages with the noindex tag.
The noindex tag is a HTML tag that tells Google (and other search engines) not to index this page

You are basically telling them "don't put this webpage on your search engine, I don't want it there."
It's also important to notice the difference between noindex, follow and noindex, nofollow.
The index tag is actually bundled with the follow tag — this all happens in the robots meta tag. Every page has got a robots meta tag, it's found in the head of your HTML.
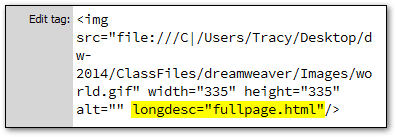
Many other tags exist in the robots meta tag, not just the index and follow ones.
The difference between noindex, follow and noindex, nofollow is simple.
Noindex, follow = Not indexed by search engines, but SEO value still passed through links on page.
Noindex, nofollow = Not indexed by search engines, no SEO value passed through links on page.
So with regards to WordPress category and tag pages creating duplicate content, we'll use noindex, follow.
Add <meta name="robots" content="noindex, follow" /> to your page head HTML.

If that's too complicated for you, just do it with a SEO plugin such as Yoast.
Takeaway: Use the noindex tag on category and tag pages (WordPress) to combat duplicate content issues.
Final Thoughts
Duplicate content is an issue that can significantly affect your SEO efforts.
Knowing how to combat it is vitally important.
Follow these best practice guidelines to avoid duplicate content altogether.
To learn more about SEO, continue reading the guides in our learning hub, and join our mastermind community group here: SERP University.