Audio Diffusion AI
AI Audio Diffusion: Music Sample Generation w/ Text-to-Audio
Diffusion models are popular right now.
The most noteworthy of these is the recently released Stable Diffusion model, but it appears that this is only the beginning. Indeed, recent work by the Harmonai team has seen diffusion models cross domains, from image generation to audio generation.
In this study, we'll look at some of the technical underpinnings of diffusion models, first focusing on their history, then on their architecture, and finally on audio creation with the Harmonai colab. Let's just get started, shall we?
🎁 Free Gift [Developers Only]: Audio diffusion repo for text-to-image stable diffusion with DreamBooth
A Brief History of Diffusion Models
Diffusion models operate by erasing and then retrieving (or noising and then de-noising) the data on which they are trained. Technically, they are inspired by Sohl-Dickstein et alnon-equilibrium .'s thermodynamics. Diffusion models are a subset of Markov random fields (MRFs) in which the Markov chain of diffusion steps gradually introduces noise into the sample data.
The model then learns to reverse the diffusion process, creating new data samples from the noise. The authors show in their 2015 paper, Deep Unsupervised Learning Using Nonequilibrium Thermodynamics, that a model may learn to reverse a diffusion process that perturbs input with noise, resulting in unique data. In addition to these bodies of work, Song et colleagues worked on score-based generative modeling in 2019 that, like diffusion models, disturbed data with several scales of noise.
However, academics did not consider the two topics - score-based generative models and diffusion models - to be more than superficially related at the time. However, in 2020, researchers demonstrated that the evidence lower bound (ELBO), a method used for training diffusion probabilistic models that allows you to rewrite intractable statistical inference problems as tractable optimization problems, is essentially equivalent to the score matching objectives used in score-based generative modeling.
Song and colleagues demonstrated in their ICLR 2021 work that score-based generative models and diffusion probabilistic models are both "discretizations to stochastic differential equations governed by score functions." Ongoing research in the diffusion space has demonstrated that it has applications not only in image reconstruction (reconstructing medical imagery), but also in a variety of other domains such as molecule generation and defending against adversarial attacks on 3-D point clouds, which could be useful in the autonomous vehicle domain. Let's look at the architecture that underpins most diffusion models today.
General Diffusion Model Architecture
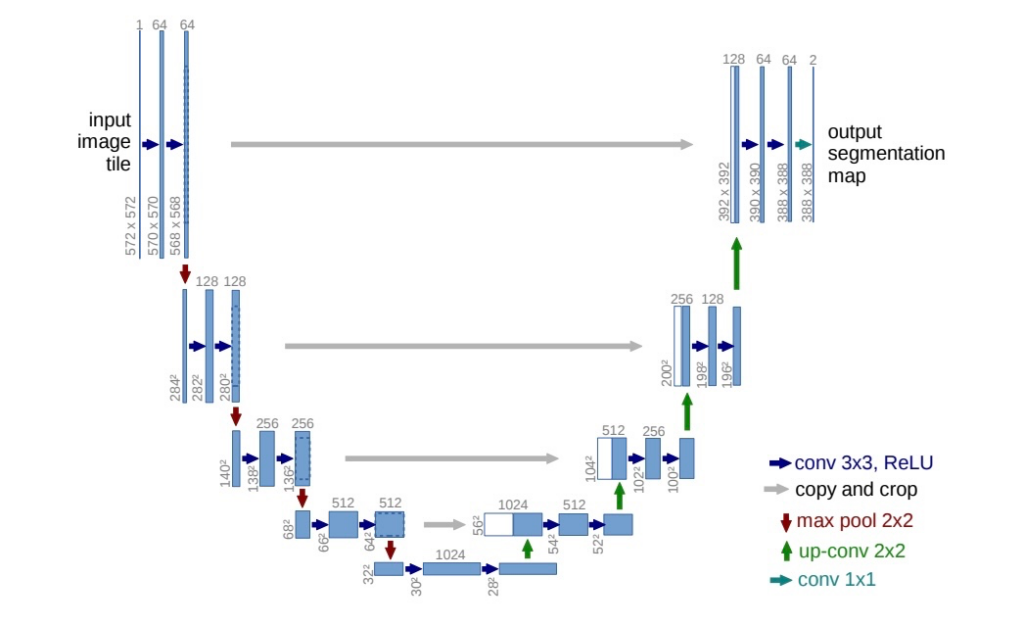
Audio Diffusion DIY
The application of diffusion models to the domain of audio is a relatively nascent area of research: beginning in the first half of 2021 a body of research emerged regarding diffusion models for:
-
de-noising text-to-speech
-
creating probabilistic models for text-to-speech, performing (neural audio) upsampling using a diffusion model
-
as well as some audio generation diffusion models for generating voice or musical outputs.
The computational complexity of some of these large diffusion models means that training a model from scratch is often out of reach of the home hobbyist, but you can experiment with pre-trained models much like how you can choose various settings for the image diffusion models.
If you're working on developing an (audio) diffusion model from scratch consider using the U-Net model from the Imagen repository as it's less resource intensive, but keep in mind the fidelity implications which are discussed on that Imagen repository issue page.
Thankfully, the researchers at Harmonai have released their inferencing repository which allows you to generate various kinds of audio data from scratch using their already-trained diffusion model (inferencing) or you can take an existing piece of music and apply one of several new styles to it:
-
honk , a style trained on Canada Geese recordings
-
glitch , an industrial-sounding music style
-
unlocked, 'unlocked' recordings provided by the Internet Archive: a style derived from hundreds of out-of-print LPs across many decades.
-
and more!
A look at Harmonai (+ a surprise)
Harmonai is a community-driven initiative that distributes open-source generative audio tools to make music composition more accessible and enjoyable for everyone. Simply put, it generates never-before-heard sounds through a process known as diffusion, in which random white noise is refined into sounds based on a pre-trained model that contains millions of parameters calculated during its training process to encapsulate the characteristics of the source material on which it was trained.
The deep learning research lab Harmonai's mission is to create open-source generative audio models, to assist researchers and developers through computing financing and a community, and to provide new creative tools to artists and audio professionals. Harmonai's mission is to make music production easier and more pleasant for everyone by developing open-source audio synthesis and modification tools.
Disco Diffusion
Dance Diffusion is similarly based on datasets made up completely of copyright-free and voluntarily donated music and audio samples. Because diffusion models are prone to memorizing and overfitting, releasing a model trained on copyrighted data may result in legal complications. Keeping any form of copyrighted material out of training data was a necessary in order to honor artists' intellectual property while also adhering to the best of their ability with the often severe copyright regulations of the music industry.
Unlike other audio generating methods, Harmonai attempts to generate production-ready sounds. This entails incorporating audio's entire auditory range. While you may definitely get away with lower quality output (in terms of bitrate) for voices to save on computation time and resource utilization, a music model must output a higher quality standard, especially if it's positioning itself to be utilized by music creators.
Dance, Dance Diffusion Revolution
Actually, just Dance Diffusion.
Consider Stable Diffusion providing just sound rather than visuals.
Dance Diffusion is an open source set of generative music diffusion models. The early models produce 1-3 seconds of audio and can also be used to interpolate and style longer audio recordings.
-
👉 Article: Chinchilla AI
-
👉 Article: Audio Diffusion
-
👉 Article: Text to Image Stable Diffusion
-
🎁 Repo: dvnBooth Text-to-Audio Diffusion
-
🎁 Repo: Text-to-Image Stable Diffusion
🎁 Free Gifts
And then... Text-to-image AI for audio?
On the way!
We are making one for you funky folks right now.
🎁 An audio diffusion repo for text-to-image stable diffusion with DreamBooth
We will be releasing a free model for ya'll soon on that too and free GPU power (could use some coding help if any of you developers are interested in building cool shit!). Sign up for the email list to be updated when that happens
Keep Reading
👉 If you like audio diffusion, you should check out Chinchilla AI.